For an AI research project at the Singapore University of Technology and Design, I developed a perception pipeline for autonomous maintenance robots. Rather than forcing a vision-language model to handle every task, I combined a YOLO zero-shot detector for fast, real-time object detection and localisation, with a vision language model for descriptive on-demand condition assessment of different objects in buildings.
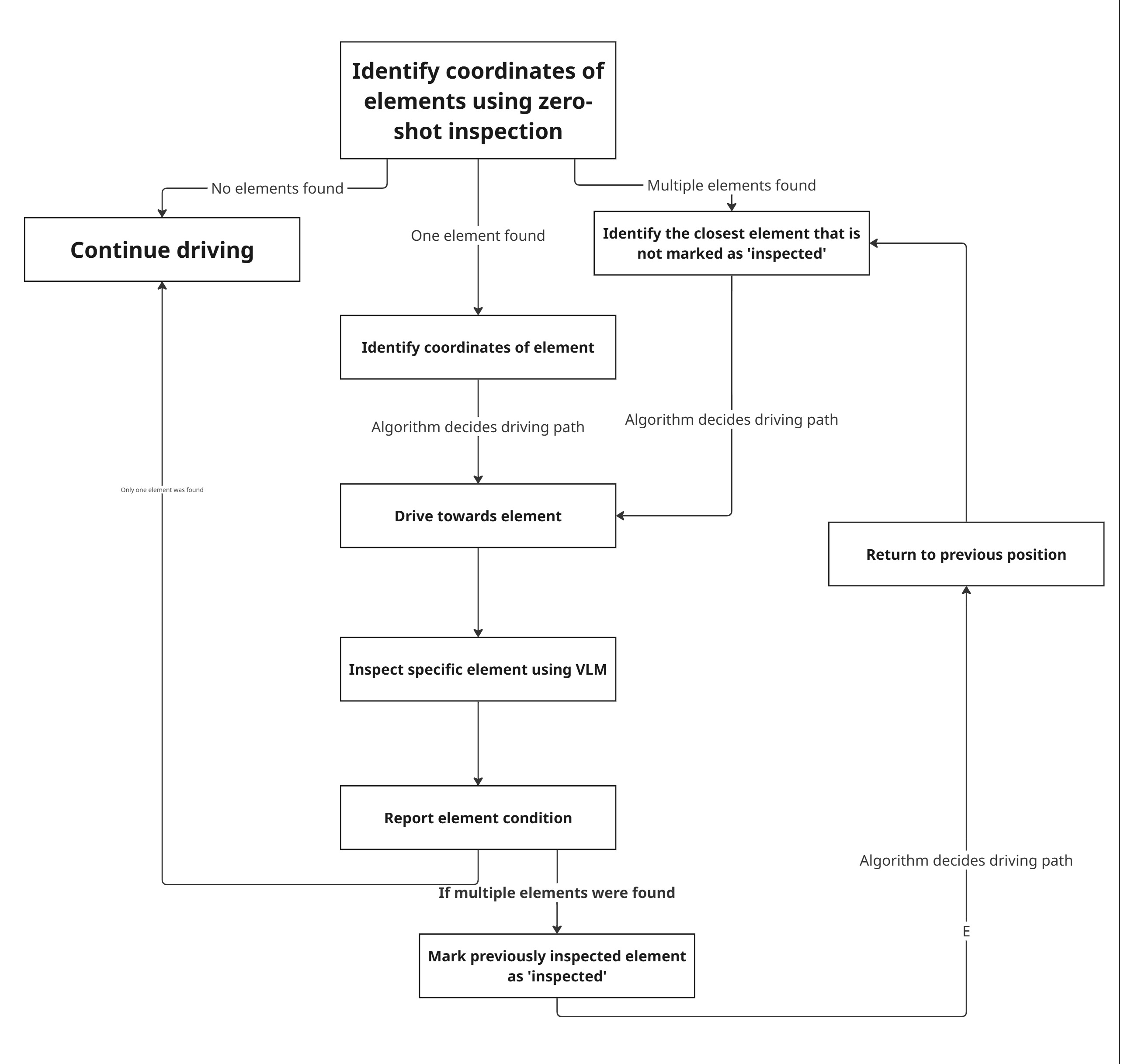
Early attempts at using LLaVA for both detection and inspection proved too slow and unreliable for real-time use. The revised pipeline separates concerns: YOLOv8x-World handles continuous frame-by-frame detection, while Gemini 2.5 Flash performs on-demand inspection of auto-cropped bounding box images.

YOLOv8x-World is an open-vocabulary model, meaning it can handle input that is not specifically in its vocabulary. The model thus requires less transfer-learning, and is also bigger than closed-vocabulary alternatives.

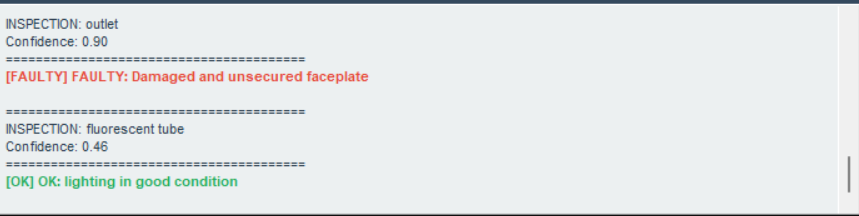
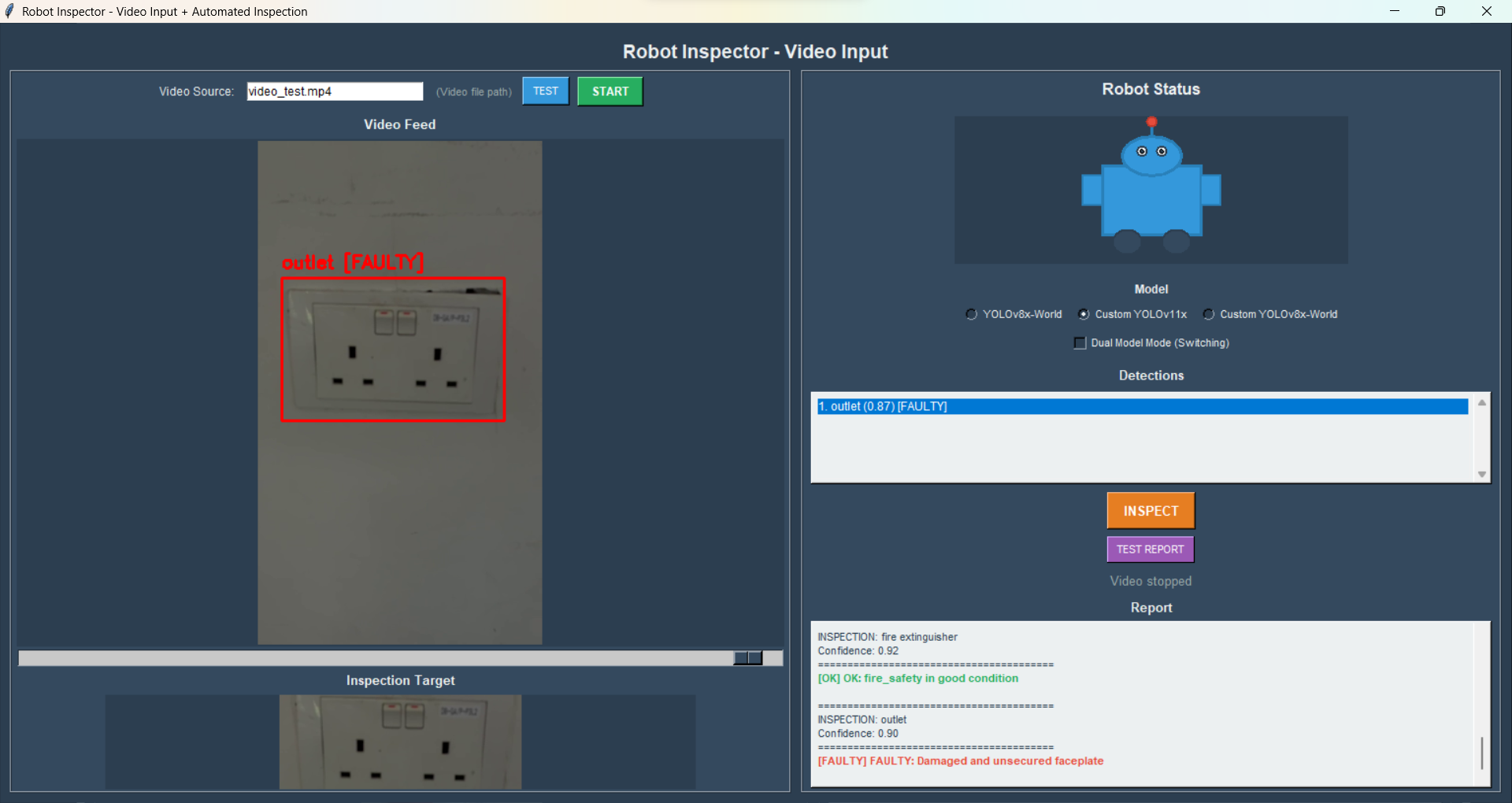
Once an object is detected, the program auto-crops the image to the bounding box and passes it to Gemini 2.5 Flash for inspection. The model returns structured OK / FAULTY reports. The Gemini cloud model is far more consistent than the open-source LLaVA model which frequently ignored output rules. Colour-coded bounding boxes (green = OK, red = FAULTY) give the robot temporary visual memory of which objects have already been assessed.
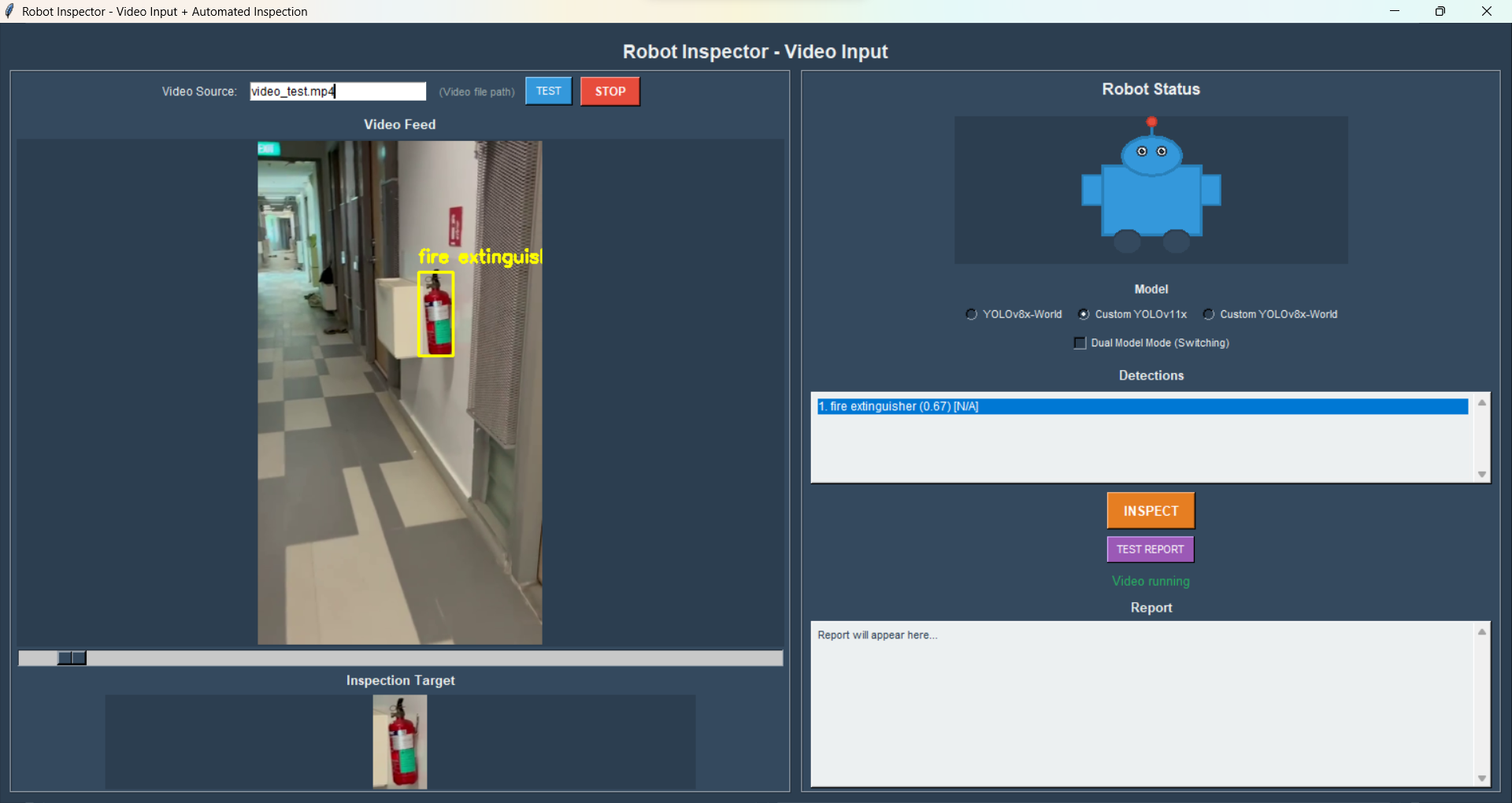
![Detection log panel showing: 1. fluorescent tube (0.49) [N/A]](../images/AI/AI_5.png)